
What if the tool you trust to catch your errors is the very thing keeping you in the dark about your site's actual availability? It's a frustrating reality for many teams. When you check the sentry status, you're often caught between two worlds: Sentry's own system health and their internal tools for monitoring your stack. You're likely tired of navigating confusing pricing models from industry giants while manually drafting status updates during a 3:00 AM outage. You need clarity, not more corporate bloat. Simple tools. No fluff.
This guide breaks down the difference between Sentry’s health and their uptime capabilities. You'll learn how to monitor your own services effectively and discover transparent, honestly priced alternatives that respect your budget. We examine how to eliminate the average 15 minute delay in manual incident reporting and automate your transparency. It's time to stop overpaying for basic heartbeat checks and start using tools that prioritize integrity over flashiness. No surprises. Just reliable monitoring.
Key Takeaways
- Distinguish between Sentry’s infrastructure health and your own uptime needs. Avoid the "all-in-one" integration trap.
- Learn how to interpret the official sentry status page and why relying on a single vendor for monitoring creates a conflict of interest.
- Move from reactive firefighting to proactive incident communication. Build trust with updates that are honest and human.
- Discover why multi-region monitoring is non-negotiable for global SaaS. Stop paying for corporate bloat and complex pricing.
- Explore a GDPR-native, EU-hosted alternative built by developers for developers. Honestly priced. No surprises.
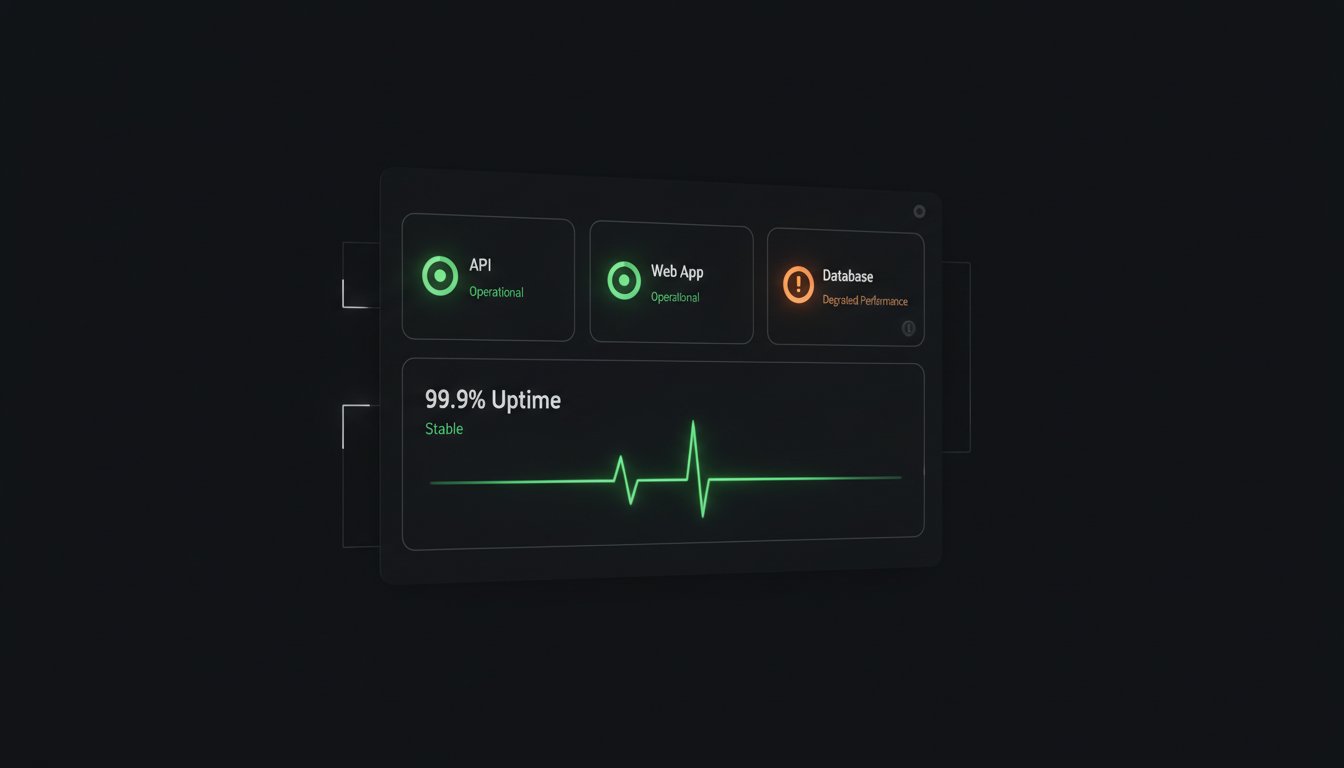
Decoding Sentry Status: System Health vs. Uptime Monitoring
Searching for sentry status often yields two very different results. One tells you if Sentry itself is broken. The other tells you if your own application is reachable. For developers, confusing these two leads to wasted hours during an incident. You need to know if the fire is in your house or at the fire station.
Checking a vendor’s status is the first step in debugging any modern stack. If their API is down, your monitoring is blind. We value transparency over corporate polish. When a tool fails, you deserve to know immediately. This section clarifies the distinction between Sentry's internal health and the tools they provide to monitor yours.
When to check status.sentry.io
When your error reporting pipeline goes quiet, don't assume your code is perfect. Check the vendor first. Silent failures happen when Sentry’s ingestion service hangs. This means errors occur in your app, but they never reach your dashboard. You see a flat line. You think everything is fine. It isn't.
Regional differences matter here. Sentry maintains separate infrastructure for US and EU users to satisfy data residency requirements. An outage in the US region might not impact a GDPR-native setup in the EU. The Sentry Status page is the definitive source of truth for their API health and real-time processing status. Use it to confirm if the problem is their infrastructure or your specific network configuration. If the status page shows green but your logs are empty, the issue is likely on your end.
The rise of Sentry Uptime Monitoring
Since late 2023, Sentry has expanded from reactive error tracking into proactive Website monitoring. This new beta tool attempts to close the gap between "my code has a bug" and "my server is unreachable." It performs HTTP tests every 60 seconds from multiple global locations. It moves the needle from "what happened" to "is it happening now."
It aims to catch DNS failures and application-level timeouts before a user reports them. However, beta products carry inherent risks. Relying on a beta for mission-critical alerts can be dangerous. Incumbents often rush features to compete, but stability is what actually saves your weekend. In its current state, the sentry status of your own app might be subject to the growing pains of a new feature set.
- HTTP tests run every minute to verify availability.
- Global probes attempt to identify regional latency issues.
- Integration with existing error logs provides a unified view.
The limitations are real. Beta tools often lack the granular frequency or the "honest" simplicity of dedicated monitors. We prefer tools that do one thing perfectly. No bloat. No surprises. Just uptime.
Sentry Uptime Monitoring vs. Dedicated Status Pages
Sentry is a titan of error tracking. It excels at showing developers exactly which line of code triggered a 500 error. But monitoring uptime is a different challenge. While Sentry Uptime Monitoring links traces to downtime, it often traps teams in a developer-centric bubble. Effective incident management requires a bridge between your backend reality and your customer's experience. Reliability isn't just about fixing bugs; it's about managing expectations.
Internal debugging vs. External communication
Sentry’s strength is the "why". It provides the deep technical context needed to fix a bug. Status pages focus on the "what". Your customers don't want to see stack traces or breadcrumbs during a crisis. They want to know if they can log in. A dedicated status page provides a clean, non-technical overview of your sentry status without the technical clutter of internal logs.
- Sentry: Deep-dive traces for engineering teams.
- Status Pages: High-level transparency for end-users.
- The Result: Reduced support tickets and increased user trust.
There is also the "observer effect" to consider. If your monitoring lives entirely inside your application suite, it might fail when your suite fails. External monitoring provides an objective perspective. It checks your uptime from multiple global regions. This ensures you see what a user in London or Frankfurt sees, not just what your internal dashboard reports.
The cost of enterprise incumbents
Many enterprise-first tools suffer from corporate bloat. They bundle uptime monitoring into complex subscription tiers that scale poorly. You shouldn't need a 45-minute sales call to set up a 1-minute heartbeat check. Small teams often end up paying for enterprise features they never touch, like advanced audit logs, just to get basic reliability data. It's a common trap in the SaaS world.
We believe in a different model. Our approach is honestly priced and built for developers who value simplicity. It is an honestly priced status page that costs €5, not $29. We keep things lean. No complex tiers. No hidden surprises. Just a reliable, GDPR-native tool that does exactly what you need. We are a small team that cares about getting the details right.
By choosing a focused tool, you avoid the integration trap. You get a dedicated communication channel that stays online even if your primary infrastructure goes dark. This is the difference between a tool that helps you fix things and a tool that helps you keep your customers. You press send. We handle the rest.
Establishing trust with your audience also requires a consistent and professional digital presence. To ensure your brand remains unified across all platforms, OS.labs focuses on organizing a brand's online presence into a coherent system.
The Transparency Gap: Why Vendor Status Isn’t Enough
Trusting a vendor to report their own downtime creates a fundamental conflict of interest. When you check the sentry status page during an outage, you are viewing data managed by the entity responsible for the failure. It is a closed loop. Your users don't care about a vendor's internal metrics; they care about their own ability to access your service. Relying solely on a provider's self-reported health is like a student grading their own exam. It lacks the objectivity required for true incident transparency.
Global SaaS applications face unique challenges that a single status page cannot solve. A localized outage in a single AWS region might affect 15% of your users in North America while leaving your European traffic untouched. Most vendor pages don't offer this level of granularity. Multi-region monitoring is essential to see what your users actually see. Without it, you are flying blind in specific markets.
Data residency adds another layer of risk. While many monitoring tools are US-hosted, European teams must prioritize GDPR compliance. Using a tool that processes heartbeat data within the EU isn't just a preference; it's a legal safeguard. Building a "trust layer" means providing your users with independent, third-party proof that your systems are functional. This layer sits between your engineering team and your customers, providing a neutral source of truth that survives even if your primary infrastructure fails.
The "Incumbent" problem in monitoring
Large platforms often lose their developer-first soul as they scale. They trade simplicity for corporate bloat and complex pricing tiers. These incumbents prioritize enterprise sales over the technical precision that small teams need. A focused, nimble team understands that details matter. They treat regional compliance as a core feature rather than an afterthought. For modern developers, "GDPR-native" is the new standard. It ensures that your monitoring stack respects privacy laws without requiring extra configuration or expensive legal reviews.
Third-party validation
Independent monitors are the only way to verify Service Level Agreements (SLAs) with total honesty. If you promise 99.9% uptime, you need a record that isn't controlled by your service provider. This prevents the "Sentry is down, so I don’t know if my site is down" paradox. When your error reporting tool fails, it shouldn't take your visibility with it. To maintain a reliable heartbeat, uptime monitoring should be decoupled from your primary SDK. This separation ensures that your status page remains live and accurate even when your main application stack is experiencing a total blackout. It's about redundancy, honesty, and keeping your users informed when they need it most.

Practical Incident Communication: Beyond the "Green Light"
Monitoring isn't just about internal alerts. It's about how you talk to your users. When your sentry status dashboard turns red, the clock starts. You don't want to be the team that stays silent for 45 minutes while Twitter mentions pile up. Transparency builds trust. Silence kills it. A 2023 study found that 80% of technical users prefer a detailed "we're fixing it" message over a generic "investigating" status. Honest communication turns a failure into a loyalty-building moment. It's the difference between a frustrated customer and a patient partner.
Drafting updates with AI
Outages are high-stress. Your hands shake. Your brain freezes. This is where "blank page syndrome" happens. StatusPulse uses a focused AI integration to help. Claude drafts the update based on your technical logs. You press send. It's that simple. You maintain control and keep the human voice. Automated tools shouldn't replace your judgment; they should remove the friction of finding words during a P1 outage. No more staring at a blinking cursor while latency spikes. We prioritize integrity over flashiness. Our AI doesn't hallucinate corporate jargon. It helps you tell the truth, faster.
Reducing support tickets
A public status page is a shield for your support team. During a 2022 incident, companies with proactive status pages saw a 50% reduction in support ticket volume. Automating the link between uptime checks and status updates stops the flood of "is it down?" emails before they start. This proactive approach lets your developers focus on the code, not the inbox.
- Isolate your infrastructure: Host your status page on separate infrastructure. If your main site is on AWS US-East-1 and it goes down, your status page shouldn't go down with it. We use diverse providers to ensure 100% reachability.
- Multi-channel reach: Use multi-channel notifications. Send updates via Email, Slack, and Webhooks. Your users shouldn't have to refresh a browser to find out you're back online.
- Precision matters: Be specific. "Database latency in Frankfurt" is better than "System issues." Precision reduces user anxiety.
Our EU-hosted, GDPR-native platform ensures your sentry status remains visible even when your primary stack faces regional trouble. We don't believe in the complex, bloated models of industry incumbents. We offer honestly priced tools that work. Four plans. No surprises. You focus on the fix; we focus on the communication.
StatusPulse: The Ethical Alternative to Sentry Status
StatusPulse is built by developers who value integrity and simplicity. We're tired of the corporate bloat that defines the monitoring industry. Our platform is EU-hosted and GDPR-native. This isn't just a legal requirement; it's a commitment to privacy that isn't just a checkbox. We don't use cookies to track your visitors. We don't store unnecessary data. We provide a clean, multi-region monitoring solution for modern applications that prioritize speed and ethics.
We believe in quiet confidence. Our infrastructure is distributed across multiple regions to ensure zero false positives. If we say your site is down, it's down. We use technical precision to give you peace of mind without the hyperbolic marketing typical of SaaS giants. By choosing an EU-hosted provider, you ensure your sentry status monitoring aligns with the highest data protection standards in the world. It's a grounded approach for teams that care about the details.
Four plans. No surprises.
Most monitoring tools force you into expensive tiers. Why pay enterprise prices for 1-minute uptime checks? We see the high-cost status quo as a barrier to honest communication. StatusPulse offers a rebellious alternative to the incumbents. Our pricing is transparent and honestly priced. For many, the choice is simple: €5. Not $29. Not $99. Just €5. We focus on the core metrics that keep your business running. This includes:
- Reliable 1-minute uptime monitoring across global nodes.
- Automatic SSL certificate tracking to prevent expired domains.
- API health checks with custom payloads and status code verification.
- Multi-region support to identify localized latency issues.
We stripped away the fluff. You don't need complex tiers to know if your site is down. You need a tool that works every single time. Our rebellious streak comes from a desire to provide professional-grade tools at a price that makes sense for startups and independent developers alike.
Getting started in minutes
You can deploy your first public status page without reading a manual. We've removed the friction. Integrating StatusPulse with your existing stack is effortless. Whether you use Slack, Discord, or PagerDuty, the setup takes seconds. Our native Jamstack support ensures your status page remains fast and reliable even when your main infrastructure is struggling. This decoupling is essential for incident transparency.
When the sentry status indicators show an outage, your users look to you for answers. Give them an honest response on a page you own. You can customize the CSS to match your brand identity in minutes. No complex configuration files. No bloated scripts. Just a clear, reliable window into your system health. Claude drafts the incident updates. You press send. It's that simple.
Own Your Incident Transparency
Effective monitoring requires more than a glance at a vendor dashboard. While Sentry excels at error tracking, relying solely on sentry status leaves a gap between internal health and user reality. Real transparency means owning the narrative when things break. You need a dedicated space that exists outside your primary infrastructure. This prevents the circular dependency of a status page going down alongside the API it monitors.
StatusPulse offers a principled way to handle these moments. We built it for developers who value regional compliance and honest pricing. Our platform is EU-hosted and GDPR-native by design. We don't believe in corporate bloat or complex tiers. Instead of struggling with manual updates during a crisis, use our AI integration. Claude drafts the update; you press send. It's a streamlined approach that respects your time and your budget. It costs €5, not $29. Choosing the right tools shouldn't be a compromise.
Stop overpaying for monitoring. Start your honest status page for €5.
Take control of your incident communication today. Your users will appreciate the honesty.
Establishing trust through uptime is vital, but so is a professional digital presence that converts; to see how specialized design and SEO can help your B2B business secure more overseas orders, check out Cheerway.
Frequently Asked Questions
How do I check if Sentry is currently down?
You can check the official sentry status by visiting status.sentry.io to view real-time health reports for their API, dashboard, and ingestion services. This page provides a transparent look at ongoing incidents and scheduled maintenance. For immediate updates during a major outage, their official X account, @getsentry, often posts alerts. If your local dashboard isn't loading, checking this page confirms if the issue is global or specific to your network.
What is the difference between Sentry Error Tracking and Uptime Monitoring?
Error tracking captures code-level exceptions after they happen, while uptime monitoring proactively checks if your server is reachable. Sentry's core product analyzes stack traces to tell you why a crash occurred. Their uptime feature, launched in 2023, functions as a heartbeat check. It pings your application at specific intervals to ensure the site is visible to users. One focuses on code health; the other focuses on network availability.
Is Sentry Uptime Monitoring free for all users?
Sentry provides a limited number of uptime checks within their free Developer plan. According to their 2024 pricing documentation, free users receive 10 monitors with a 1 minute frequency at no cost. If you require more than 10 monitors or more frequent pings, you must transition to a paid tier. This makes it a practical entry point for small teams, though growing operations often require more robust, dedicated status tools.
Why should I use an EU-hosted status page instead of a US-based one?
EU-hosting keeps your incident data within European jurisdiction, which simplifies GDPR compliance for your legal department. Many industry incumbents host data in US-East-1, creating potential data sovereignty issues for European companies. StatusPulse is GDPR-native and hosted in Germany. This regional focus reduces latency for your local users and ensures you aren't caught in the legal complexities of the EU-US Data Privacy Framework.
Can I use StatusPulse alongside Sentry for my DevOps stack?
Yes, you can use StatusPulse to communicate your system health and the current sentry status to your end users. While Sentry helps your developers find and fix bugs, StatusPulse manages the human side of an incident. You can connect your monitoring tools to our API to automate status updates. This approach separates your internal debugging environment from your public-facing transparency dashboard, keeping your customers informed without showing them raw logs.
How does AI incident management work in StatusPulse?
Our AI integration streamlines communication during high-pressure outages by drafting incident reports for you. Claude drafts the update based on your technical input, then you press send. It eliminates the stress of writing clear, professional copy while your servers are down. You keep total control over the final text. This ensures your updates are fast and honest, avoiding the robotic or vague language common in manual incident reports.
What happens to my status page if my main server goes down?
Your status page stays online because it's hosted on a completely separate infrastructure from your primary application. We use a Jamstack architecture across multiple regions to ensure 100 percent availability. Even if your main cloud provider experiences a total regional failure, your customers can still access your status updates. We don't share your failure points. Reliability is our core mission, so we keep your communication channel open when you need it most.


