Last Tuesday, a senior DevOps lead watched their multi-region app go dark because of a dangling CNAME record. Every server health check was green, but the site was unreachable for 15% of their global users. You've likely felt that same pit in your stomach. It's frustrating when your monitoring dashboard says everything is fine while your support queue says otherwise. Standard uptime checks don't catch silent record drift until it's too late.
In this guide to DNS Monitoring 101: Detecting Record Changes Before They Break Production, you'll learn how to stop reacting to outages and start preventing them. We'll show you how to align with the NIST SP 800-81 Revision 3 standards, published on March 19, 2026, which reposition DNS as a critical security enforcement layer. We'll explore how to use modern ECDSA cryptography and encrypted protocols to secure your records. You'll finish this article with a clear strategy for zero-downtime migrations and a setup that alerts you the second your records deviate from your source of truth.
Key Takeaways
- Standard uptime checks miss DNS drift. Learn why a healthy server doesn't guarantee a reachable website.
- Identify the five essential records you must track. Protect your mail flow and traffic routing from silent failures.
- Master DNS Monitoring 101: Detecting Record Changes Before They Break Production to eliminate propagation lag surprises.
- Establish a baseline and set one-minute check intervals. Catch unauthorized changes before they reach your global users.
- Discover how StatusPulse offers honestly priced, GDPR-native monitoring. It's built for developers who value simplicity over corporate bloat.
What is DNS Monitoring and Why Uptime Checks Aren’t Enough
DNS monitoring is the continuous verification of authoritative records to ensure they match your intended configuration. Most engineering teams rely on standard uptime checks to keep their services running. They ping a server. They wait for a 200 OK status. But this only verifies the destination. DNS monitoring verifies the map. If the map is wrong, your users will never find the destination, regardless of how healthy your servers are. This is the fundamental lesson of DNS Monitoring 101: Detecting Record Changes Before They Break Production.
The Domain Name System (DNS) acts as the internet's routing layer. When a record is modified without your knowledge, users end up at the wrong IP address or a dead end. We call this the "Healthy Server Trap." Your application is 100% healthy. Your database is fast. Your load balancer is green. Yet, your traffic drops to zero because a record was modified or deleted. Uptime monitors won't alert you because the server they are checking is technically "up." They are looking at the house, not the street sign pointing to it.
The Silent Nature of DNS Failures
DNS issues are rarely universal. They are fragmented by geography and ISP. A customer in Berlin might see a 404 error while a developer in New York sees a perfectly functioning homepage. This happens because of caching. When a record changes, it doesn't update everywhere at once. Caching layers at the ISP level can hold onto old, stale data for hours. If a mistake is made, your internal team might see "it works" because their local cache hasn't refreshed yet. TTL (Time to Live) values dictate this delay. High TTLs mean a single typo can take 24 to 48 hours to fully resolve across the globe. You can't fix what you can't see. You can't see DNS failures without active monitoring.
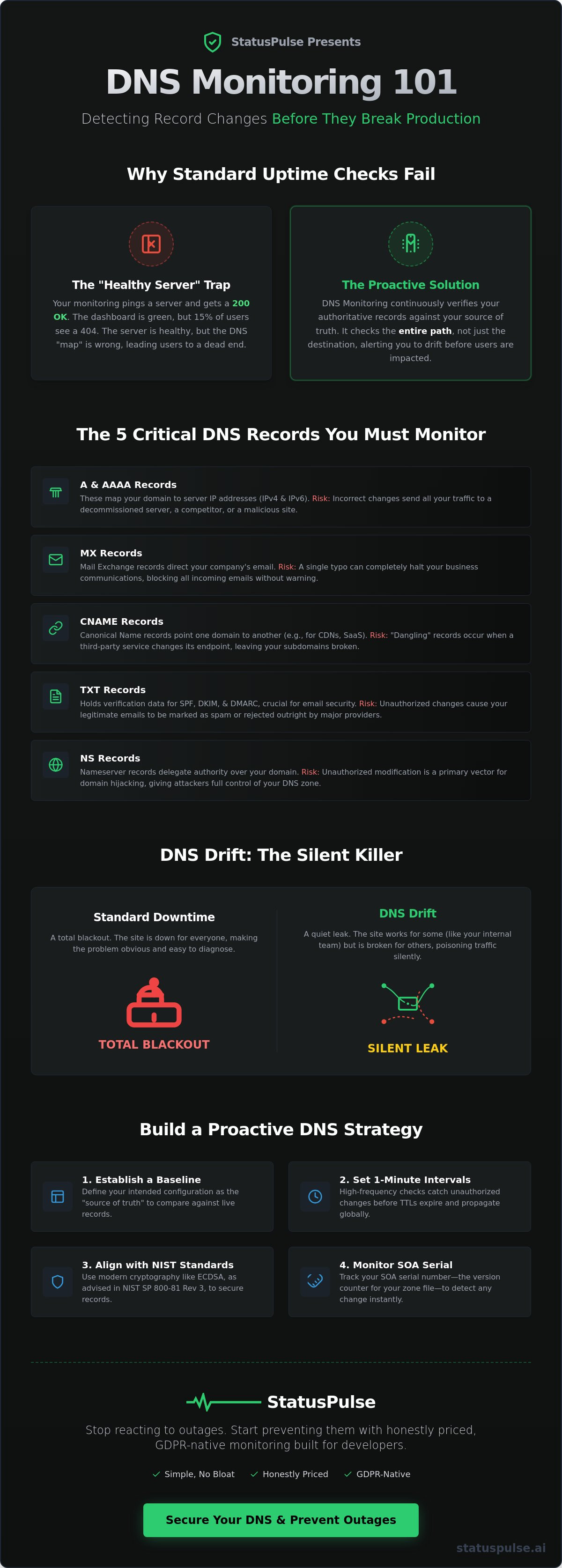
DNS Drift vs. Standard Downtime
Infrastructure drift occurs when your live environment deviates from your source of truth. In a DNS context, this often means a developer manually changed a record in a provider portal and forgot to update the configuration file. Manual record audits are a recipe for production outages. They are slow and prone to human error. There's a critical difference between resolution failure and incorrect resolution. A resolution failure is obvious; the site won't load. Incorrect resolution is dangerous; the site loads the wrong content or sends data to the wrong server. Standard downtime is a total blackout. DNS drift is a quiet leak that poisons your traffic. At StatusPulse, we believe monitoring should be as simple as it is honest, catching these drifts before they become catastrophes.
The 5 Critical DNS Records You Must Monitor
Effective monitoring isn't about watching every obscure entry in your zone file. It's about identifying the bedrock records that keep your business alive. In DNS Monitoring 101: Detecting Record Changes Before They Break Production, we focus on the five pillars of domain health. If these drift, your infrastructure fails. DNS drift isn't just a technical failure; it's the specific delta between your intended configuration and the public record. It's the silent divergence that happens when automated scripts or manual edits go wrong without an audit trail.
- A and AAAA Records: These map your hostname to IPv4 and IPv6 addresses. They are your primary routing layer. Even a minor IP change can send your users to a decommissioned server or a malicious clone.
- MX Records: Mail Exchange records handle your email routing. A single character typo in your priority settings or server name will kill your business communication instantly.
- CNAME Chains: Modern apps rely on SaaS aliases. When a third-party provider changes their endpoint without notice, your CNAME "breaks," leaving your subdomains orphaned.
- TXT Records: These hold your SPF, DKIM, and DMARC data. If these records drift, your legitimate emails will be flagged as spam or rejected by major providers like Gmail and Outlook.
- NS Records: Nameserver records define who has authority over your zone. Unauthorized changes here are often the first sign of domain hijacking.
Monitoring these records is a core part of maintaining DNS security best practices. Most teams check these once a year during a security audit. That's a mistake. You need real-time verification to catch errors before propagation finishes and the damage becomes permanent.
Monitoring the SOA Serial Number
The Start of Authority (SOA) serial number is a version counter for your DNS zone. It tells secondary nameservers when to update their records. If your primary and secondary servers desync, you'll experience regional outages where some users see the old site while others see the new one. SOA monitoring prevents primary/secondary nameserver desync by alerting you when the serial numbers don't match across your global infrastructure. It's a simple check that prevents massive headaches.
Security Records: CAA and DNSSEC
Security goes beyond resolution. CAA records specify which Certificate Authorities are allowed to issue SSL certificates for your domain. Monitoring these prevents unauthorized parties from generating fraudulent certs. Additionally, DNSSEC validation is essential for preventing cache poisoning attacks that redirect traffic to malicious IPs. At StatusPulse, we integrate this with our SSL certificate monitoring for total domain health. It's a straightforward approach to a complex problem. No bloat. Just the data you need to stay online. If you're tired of complex enterprise tools, you can start monitoring your records honestly today.
How DNS Record Changes Break Production
You hit save. The damage begins. Unlike a code rollback that takes seconds, a DNS error is a global commitment. This is the core challenge of DNS Monitoring 101: Detecting Record Changes Before They Break Production. Once a record is published, it lives in caches across thousands of ISPs. A "quick fix" for a typo doesn't work instantly. You're at the mercy of the propagation cycle. This window often lasts 24 to 48 hours. During this time, your traffic is split between the old, working IP and the new, broken one. It's a partial outage that is notoriously difficult to debug without active tracking.
Changing a CDN provider is another common trigger for production failure. If you migrate vendors and update your CNAME records, orphaned subdomains can lead to "SubdoMailing" attacks. Malicious actors take over these dangling records to send spam or host phishing pages under your brand. It's a silent failure that destroys your reputation. Similarly, configuration errors in your TXT records can destroy your sender reputation. A single missing character in your SPF record can lead to 100% of your business emails being blacklisted by major providers. This isn't just a technical glitch. It's a total block on customer communication.
We also see "split-horizon" desync issues. This happens when your internal office DNS says one thing, but the external world sees another. Your team thinks the site is up. Your customers know it isn't. You can't rely on "it works for me" as a verification strategy. You need a neutral, external perspective.
Case Study: The $10k Typo
Consider a mid-sized e-commerce firm that updated its MX records on a Friday afternoon. A small typo in the priority field went unnoticed. For 12 hours, every "Order Confirmation" and "Support Request" email vanished. By the time the team realized the issue, they had lost an estimated $10,000 in missed sales and support escalations. Reactive troubleshooting took four hours to identify the root cause. With proactive monitoring, the team would have received an automated alert in 60 seconds. The cost of an automated alert is negligible compared to the cost of a missed business day.
Detecting Unauthorized Changes
Shadow IT is a growing risk. Roughly 35% of IT spending happens outside the sight of the DevOps team. Marketing departments often add tracking pixels or subdomains without a formal review. These unauthorized changes can break your security posture or conflict with existing records. Monitoring acts as a continuous audit log for compliance. It helps you identify malicious record hijacking before your traffic is redirected to a phishing site. Following the NIST SP 800-81 Revision 3 guidelines from March 19, 2026, requires this level of active oversight. At StatusPulse, we provide the tools to catch these drifts before they turn into headlines. No complex enterprise bloat. Just the truth about your records.
Best Practices for a Proactive DNS Monitoring Strategy
Reaction is a choice. You can wait for the support tickets to flood in, or you can build a system that alerts you before the first user notices a problem. Building a robust strategy is the next logical step in DNS Monitoring 101: Detecting Record Changes Before They Break Production. It starts with establishing a baseline. You must document and store your current authoritative records. Without a known source of truth, drift is impossible to quantify. Most teams skip this step, assuming their provider's portal is the only record they need. That is a mistake. Portals fail. API keys leak. You need an independent snapshot.
Once you have a baseline, implement these four steps for maximum reliability:
- Step 1: Baseline your records. Verify your configuration across all authoritative nameservers, not just the primary one.
- Step 2: Set 1-minute check intervals. For critical A and MX records, five-minute checks are too slow. Seconds matter when an incorrect record starts propagating.
- Step 3: Multi-region monitoring. DNS is regional. Verify resolution from the EU, US, and Asia to catch localized cache poisoning or latency spikes.
- Step 4: Integrate with your status page. When a change is detected, update your public status page automatically. Transparency builds trust with your users.
If you want to move away from complex enterprise bloat, you can start monitoring your DNS records with a tool that values your time and privacy.
Reducing Alert Fatigue
Nothing kills a DevOps culture faster than noisy alerts. To stay sane, only alert on "Authoritative" changes. Resolver glitches happen constantly due to ISP instability. These are false positives. You only care if the record on your authoritative nameserver has drifted. Set up Slack or Discord notifications so your team sees these changes in their existing workflow. At StatusPulse, we believe in honest pricing. You shouldn't pay for enterprise features you don't use. We provide high-frequency checks without the corporate tax typical of industry incumbents.
Preparing for DNS Migrations
Migrations are the most dangerous time for your domain. To minimize risk, lower your TTLs to 300 seconds (5 minutes) at least 24 hours before the move. This ensures that any mistakes can be corrected quickly. Use active monitoring to verify propagation in real-time as you switch nameservers. You can also verify global resolution using uptime monitoring to ensure your new IP addresses are reachable from every continent. This proactive approach turns a high-stress event into a routine update. It's about quiet confidence in your infrastructure. No surprises. Just uptime.
Honestly Priced Monitoring: The StatusPulse Advantage
StatusPulse isn't another faceless monitoring giant. We're a small team that cares about getting the details right. Our platform provides a native integration between DNS checks, SSL monitoring, and public status pages. This unified approach is the final piece of DNS Monitoring 101: Detecting Record Changes Before They Break Production. By keeping your monitoring and communication in one place, you eliminate the friction that causes extended outages. You don't need a complex ecosystem. You need a system that works.
We believe in technical precision and plain-spoken ethics. That's why StatusPulse is EU-hosted and GDPR-native. We don't just follow privacy laws; we build them into our architecture. For developers who value regional compliance, this isn't a marketing afterthought. It's a core virtue. We prioritize integrity over flashiness, providing a grounded, honest approach to infrastructure health.
Beyond the Incumbents
Industry incumbents love complexity. They hide actual costs behind sales calls and enterprise tiers. We chose a different path. Honestly priced monitoring starts here. You get a simple, punchy interface designed for quick action. No corporate bloat. No hidden fees. You can visit the StatusPulse homepage and have your first check running in less than five minutes. It's as streamlined as the software itself.
Our value proposition is bold and clear: €5, not $29. We provide the same high-frequency monitoring as the giants without the unnecessary markup. Four plans. No surprises. This transparency extends from our pricing to our product design. We're the fair alternative for users who are tired of complex models and corporate bloat.
Incident Communication Made Simple
The hardest part of a DNS failure isn't the technical fix. It's explaining to a non-technical customer why they see a 404 while your team sees a working site. Most guides ignore this communication gap. We solve it with AI-powered incident management. Claude drafts your DNS outage updates; you press send. It translates complex concepts like propagation lag and record drift into clear, reassuring language. This respects your user's time and reduces your stress.
Building trust requires honesty. A public status page is your best PR tool during a crisis. It shows your users that you're aware, active, and transparent. When things break, you don't need a complex manual. You need a tool that respects your agency. Start monitoring for €5, not $29. No surprises. Just reliable data and clear communication. This is how you master DNS Monitoring 101: Detecting Record Changes Before They Break Production and maintain a professional edge.
Secure Your Infrastructure and Your Reputation
Uptime monitoring tells you a server is alive. DNS monitoring tells you it's reachable. You've seen how a single record typo can lead to a $10,000 loss or a 48 hour propagation nightmare. By baselining your records and setting one minute check intervals, you eliminate the "it works on my machine" excuse. Mastering DNS Monitoring 101: Detecting Record Changes Before They Break Production is about moving from reactive firefighting to quiet, confident oversight. To further bolster your security, offensive security assessments from Pentesys Limited can help you identify and mitigate risks before they can be exploited. You now have the framework to align with the NIST SP 800-81 standards from March 19, 2026, and protect your domain from silent drift.
You deserve a tool that respects your time and your ethics. StatusPulse offers an EU-hosted, GDPR-native solution that avoids the complexity of industry incumbents. Our AI-driven incident management helps you communicate clearly when things go wrong. Claude drafts the updates. You press send. It's honestly priced monitoring with zero surprises. Stop guessing and start monitoring. Get StatusPulse for €5/month. Your infrastructure is too important to leave to chance. Keep your records straight, your latency low, and your status page green. It's time to monitor with integrity.
Frequently Asked Questions
What is the difference between DNS monitoring and uptime monitoring?
Uptime monitoring verifies your server is responding; DNS monitoring ensures the world knows how to find it. While a standard check might show 100% availability, your users see errors if the A record points to the wrong IP. DNS monitoring tracks the integrity of your records at the authoritative source. It's the difference between checking the building and checking the street signs. One monitors the destination, while the other monitors the map.
Can DNS monitoring detect if my domain is being hijacked?
Yes, DNS monitoring detects hijacking by alerting you to unauthorized changes in your NS records. If a malicious actor gains access to your registrar, they often point authority to their own servers first. Monitoring these records provides an immediate audit log of changes. This visibility is a core pillar of DNS Monitoring 101: Detecting Record Changes Before They Break Production. You catch the shift before traffic is fully redirected to a malicious clone.
How often should I check my DNS records for changes?
You should check critical records like A, MX, and CNAME every 60 seconds. Propagation can take 24 to 48 hours to fully resolve across global ISPs, so every minute you delay detection extends the duration of your outage. Low-priority records can be checked less frequently, but production infrastructure requires high-frequency verification. This ensures you catch drift before stale data spreads across global caches and becomes difficult to purge.
Will DNS monitoring slow down my website performance?
No, DNS monitoring has zero impact on your website's load time or server performance. The checks are performed out-of-band, meaning they query nameservers directly rather than routing through your application or web server. These queries are lightweight and happen in the background. Your users will never experience latency or resource contention because of your monitoring setup. It's a non-intrusive way to maintain infrastructure health without adding overhead to your stack.
What happens if my nameservers are out of sync?
When nameservers are out of sync, your users experience inconsistent resolution or regional outages. Some visitors will reach the correct IP while others hit a dead end or an old version of your site. This often happens when the SOA serial number fails to update on secondary servers. Monitoring the SOA record across your entire infrastructure prevents these partial failures. It ensures that 100% of your nameservers are serving identical, up-to-date information to the public.
Do I need DNS monitoring if I use a managed provider like Cloudflare?
Yes, you need an independent source of truth outside your primary provider. Managed providers are reliable, but human error or API misconfigurations can still lead to record drift. Roughly 35% of configuration errors happen during manual updates in provider portals. External monitoring ensures that what the public sees matches your intended configuration. It acts as a neutral third party that verifies your provider is actually serving the records you have set.
How does DNS propagation affect my monitoring alerts?
Propagation doesn't change the alert itself, but it defines the window you have to react. Once an incorrect record is cached by global resolvers, you can't undo it instantly. Monitoring alerts you the moment the change hits your authoritative nameserver. This is why DNS Monitoring 101: Detecting Record Changes Before They Break Production emphasizes early detection. You want to revert the change before it spreads to your entire user base and stays there for 48 hours.
Can I monitor TXT records for email security with StatusPulse?
Yes, StatusPulse allows you to monitor TXT records to protect your email deliverability and security. Drift in SPF, DKIM, or DMARC records is a leading cause of emails being flagged as spam by providers like Gmail. By tracking these entries, you ensure your mail authentication remains valid. It's a simple way to maintain your sender reputation without needing complex, overpriced enterprise suites. We keep it honest; you get the security you need for €5, not $29.