

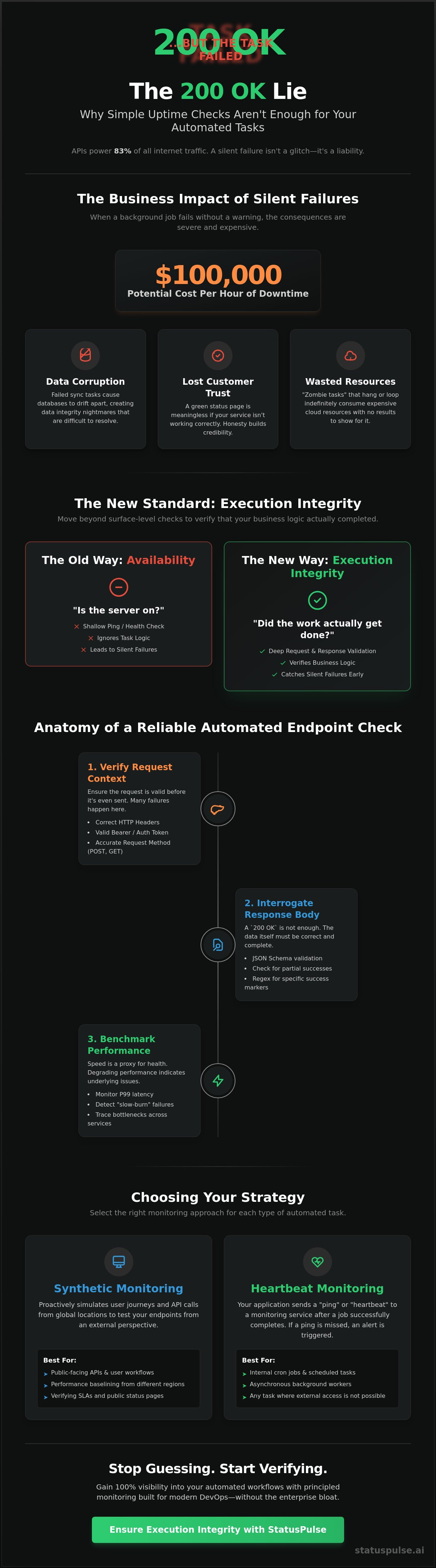
A 200 OK status code is the industry’s favorite lie. It tells you the server is awake, but it doesn't guarantee your automated task actually finished. Effective API endpoint monitoring for automated tasks is now a requirement, especially with APIs powering 83% of all internet traffic. A silent failure in a background workflow is more than a glitch. It's a liability that can cost $100,000 per hour. You need more than a heartbeat check to ensure execution integrity.
We understand the frustration of alert fatigue from noisy, non-critical monitors. It's exhausting to manage complex tools built for an era of enterprise bloat. You deserve 100% visibility into your workflows without the unnecessary friction. This guide will show you how to master reliable monitoring for internal and public endpoints alike. We will explore how to reduce your Mean Time to Recovery (MTTR) and provide honest data for your public status pages. It's time to move past simple uptime and start verifying that your work is actually getting done.
Key Takeaways
- Move beyond simple uptime checks to catch silent background failures before they impact your data.
- Identify the essential elements of a reliable check, from auth token verification to JSON payload validation.
- Choose between synthetic and heartbeat strategies to build robust API endpoint monitoring for automated tasks without the enterprise bloat.
- Reduce MTTR by implementing tiered alerting and task-specific Service Level Objectives.
- Connect your monitoring workflows to public status pages for seamless, honest communication with your users.
Why Automated Tasks Require Specialized API Monitoring
Automated tasks are the quiet backbone of your infrastructure. They handle the repetitive work that keeps your business moving. But silence is dangerous. When a background script fails, there is no user to complain. No one sees the error message. API endpoint monitoring for automated tasks changes this dynamic. It provides a window into these hidden processes. It ensures that your background work is actually happening. This specialized monitoring verifies the full execution lifecycle, from the initial trigger to the final data commit.
Execution integrity is the new standard for 2026 automation, moving beyond simple availability to verify that business logic actually completed.
The Limits of Basic Uptime Checks
Standard uptime checks are too shallow for background jobs. They look at the surface. A 200 OK status code often lies. It says the server received the request. It doesn't say the task finished. This leads to zombie tasks. These are processes that consume resources but fail to deliver results. They are ghosts in the machine. Unlike user-facing calls, automated workflows have no immediate feedback loop. You need a monitor that understands the difference between a simple ping and a completed job. Without this, you're just monitoring the door, not the person inside doing the work.
The Business Impact of Silent Failures
The fallout of silent failures is expensive. Data corruption is the primary threat. If a sync task fails, your databases drift apart. This creates a mess that takes days to clean. Customer trust is also at stake. If your status page is green while the data is wrong, you lose credibility. Modern API management demands a higher level of honesty. You can't afford to be the last to know your system is broken.
Silent failures also hit your wallet. Tasks that loop indefinitely or hang without timing out drive up cloud costs quickly. At StatusPulse, we believe monitoring should be straightforward. No bloat. No hidden fees. Just reliable data to keep your automation on track. We help you avoid the resource drain of failed tasks while keeping your public status accurate. It's about precision and ethical software management.
Anatomy of a Reliable Automated Endpoint Check
A reliable check is more than a ping. It is a rigorous interrogation. For API endpoint monitoring for automated tasks, the process begins before the data even arrives. You must verify the request context. Are the headers correct? Is the Bearer token still valid? Many systems fail because of expired credentials, yet the monitor reports a connection error. This is a distinction that matters. High-quality API monitoring identifies exactly where the chain broke. It separates authentication issues from infrastructure downtime.
Execution integrity requires a deep dive into the payload. It isn't enough to see a 200 OK. You need to know the work happened. For a deeper look at these standards, see our guide on API Monitoring: The Developer’s Guide to High Availability in 2026. We focus on the technical precision that keeps systems online.
Validating the Response Body
Data integrity is the ultimate goal. Use JSON schema validation to enforce strict structure. Don't just look for a success flag. Verify that the expected fields exist and contain valid data types. If your automation processes batches, you must check for partial successes. A task that completes only 50% of its work shouldn't be ignored. Use regex to find specific success markers deep within the response. This prevents "silent successes" where the API returns a valid but empty result set. Accuracy is non-negotiable.
Performance Benchmarking for Automation
Speed is a proxy for health. High-frequency tasks rely on consistent latency. Watch your P99 metrics closely. A sudden spike is obvious, but a "slow-burn" failure is harder to see. This happens when latency creeps up slowly over weeks. It often points to database bloat or unoptimized queries. Using OpenTelemetry allows you to trace these bottlenecks across internal services. It gives you the "why" behind the slowdown. Reliable API endpoint monitoring for automated tasks requires this level of precision.
We built StatusPulse to handle this level of technical detail without the corporate bloat. Our tools focus on the metrics that actually impact your reliability. No flashy charts you'll never use. Just the data you need to keep your automated workflows running perfectly. We prioritize your time and your system's integrity.
Synthetic Monitoring vs. Heartbeat Pings: Choosing Your Strategy
Choosing between a pull or a push strategy depends on your specific architecture. API endpoint monitoring for automated tasks is not a one-size-fits-all solution. Synthetic monitoring is a pull mechanism. It acts like an external auditor. The monitor proactively calls your API to verify health from the outside. Heartbeat monitoring is a push mechanism. It acts like a check-in. Your task tells the monitor when it has successfully crossed the finish line. For critical infrastructure, a hybrid approach is the only way to sleep soundly. It covers both reachability and execution.
Push monitoring is superior for long-running cron jobs because it eliminates the risk of an external monitor timing out while your script is still processing data.
When to Use Synthetic API Checks
Synthetic checks are the gold standard for public endpoints. If you rely on third-party integrations, you need to know their status before your customers do. These checks simulate complex user journeys. They can chain multiple API calls together to verify a complete workflow. Synthetic monitors also handle the essential maintenance tasks. They verify SSL certificate validity and ensure your DNS is resolving correctly. It is an outside-in perspective. It catches network-level failures that your internal logs might ignore. Use this for everything your users touch directly.
The Power of Heartbeat (Cron) Monitoring
Heartbeat monitoring solves the fire and forget problem. Internal scripts often run in total darkness. If the server hosting your cron job dies, the task never starts. A synthetic monitor cannot see a task that doesn't exist. Heartbeat monitoring alerts you when it hears nothing. If your task fails to ping the monitor within its expected window, you get an alert. This is the most reliable way to catch dead servers or crashed background daemons. Implementation is fast. You don't need heavy enterprise agents. A simple curl command at the end of your script is enough. It is lightweight, ethical, and effective.
At StatusPulse, we believe in keeping things simple. We provide both synthetic and heartbeat tools so you can build the right strategy for your team. You shouldn't have to choose between complexity and visibility. We give you the precision of an enterprise suite without the corporate bloat or confusing pricing. It's about giving you the data you need to maintain execution integrity across every automated workflow you own.
Best Practices for Monitoring Automated Workflows in 2026
Reliability is a habit, not a feature. To succeed with API endpoint monitoring for automated tasks, you must establish clear Service Level Objectives (SLOs). These aren't just technical targets. They represent your commitment to data integrity. If a synchronization task takes five minutes instead of thirty seconds, it has failed your SLO. Define these thresholds for every critical workflow. Precision matters more than simple uptime.
Tiered alerting is your defense against burnout. Not every failed ping requires an immediate response. Categorize your alerts by impact. A non-critical data export failure can wait until morning. A broken payment gateway sync cannot. A disciplined approach to API endpoint monitoring for automated tasks prevents the alert fatigue that leads to missed outages. It keeps your team focused on what actually matters.
Transparency is a core virtue. Automate your public status page updates. When a monitor detects a failure, your users should see it immediately. This builds a foundation of trust. It also reduces the load on your support team during an incident. Finally, audit your monitors quarterly. Delete the "ghost" checks from legacy projects. A lean monitoring suite is a precise one. Avoid the clutter of unnecessary data.
Setting Intelligent Alert Thresholds
Avoid the "boy who cried wolf" syndrome. Alert flapping protection is essential. It prevents a flurry of notifications when a connection is unstable. Modern AI incident management tools now distinguish between transient blips and genuine outages. These systems accurately identify over 85% of anomalies, effectively silencing the noise that plagues traditional tools. If a failure persists, your escalation policy should kick in. Move from a Slack notification to a phone call only when the situation demands it.
Security and Privacy in API Monitoring
Privacy is a right, not an option. Ensure your monitoring logs redact sensitive information. This is critical for remaining GDPR compliant when handling user data. We prioritize geographic hosting standards. Using EU-based infrastructure ensures your metadata stays within strict regulatory boundaries. Never hardcode API keys in your checks. Use secure secret management to protect your credentials. Ethical monitoring respects both your data and your users.
Ready to build a more reliable system? Start monitoring your automated APIs with StatusPulse today. We provide the precision you need without the corporate bloat.
StatusPulse: Principled Monitoring for Modern DevOps
StatusPulse is the antidote to enterprise bloat. We built a platform for specialists who value precision over flashy, useless features. Many industry incumbents hide behind complex pricing models and corporate tiers. We don't. We provide a focused alternative to massive monitoring suites. Our platform offers native integration between API monitoring and public status pages. This ensures your users stay informed without manual intervention. It's about maintaining execution integrity across your entire stack. We prioritize honesty and technical depth.
Incident communication is often an afterthought in automation. We changed that. Our AI-powered incident management drafts honest updates for you during a crisis. It identifies why a task failed and suggests the right language to inform your stakeholders. This principled approach reduces the stress of technical disruptions. For a deeper look at our philosophy, read our guide on Uptime Monitoring: A Developer’s Guide to Reliability and Honest Communication. We believe in transparency as a core virtue of DevOps.
Setup Your First Monitor in 60 Seconds
You can add a new API endpoint check via the StatusPulse dashboard in under a minute. The process is straightforward. No sales calls or lengthy onboarding. Configure global vantage points to check latency from every continent. This ensures your API endpoint monitoring for automated tasks catches regional issues immediately. You can verify headers, auth tokens, and payload patterns with a few clicks. Connect your monitor to a public status page for instant transparency. It's a streamlined workflow for busy teams.
AI-Driven Incident Summaries
Outages are stressful. Explaining them shouldn't be. StatusPulse uses AI to explain why an automated task failed. Modern anomaly detection now catches over 85% of issues, but the "why" is what matters to your team. Our AI SRE agents assist with root cause analysis. They analyze the error and draft a clear summary for your status page. This reduces the pressure during a downtime event. You get a pre-drafted report that is ready for a final human action. It is API endpoint monitoring for automated tasks designed to respect your time and your intelligence. We focus on solving problems, not just reporting them.
Mastering Execution Integrity
Uptime is no longer the sole metric of success. You need to verify that your business logic actually completes every time. Reliable API endpoint monitoring for automated tasks transforms your background workflows from a black box into a verified source of truth. By combining synthetic checks with heartbeat pings, you eliminate the threat of silent failures that drain resources. You've learned how to set intelligent thresholds and maintain strict security standards. Now, it's time to put those principles into practice.
We built StatusPulse to provide a zero-bloat developer experience for teams that value technical precision. Our platform prioritizes your privacy with EU-based hosting standards and simplifies recovery with AI-powered incident summaries. You shouldn't have to navigate complex enterprise pricing just to get honest data. It is time to stop guessing and start knowing exactly how your systems perform. Build trust with transparent monitoring at StatusPulse. Your automation deserves a higher standard of reliability.
Frequently Asked Questions
What is the difference between API monitoring and website uptime monitoring?
Website uptime monitoring checks if a visual page loads correctly for a human user. API monitoring focuses on data correctness and response integrity. It validates status codes, headers, and specific JSON schema patterns. While a website check tells you if the door is open, API monitoring verifies the conversation happening inside. It is the only way to ensure your background services are exchanging valid data.
Can I monitor internal API endpoints that are not accessible via the public internet?
You can monitor internal endpoints using heartbeat pings. This push method allows your internal script to notify an external monitor upon success. It doesn't require opening your firewall to the public internet. Alternatively, some teams use private monitoring agents within their own network. This keeps your internal architecture secure while maintaining 100% visibility into task execution.
How often should I run health checks on my automated API endpoints?
Frequency depends on the criticality of the workflow. For high-frequency synchronization, checks every 1 to 5 minutes are standard. For daily cron jobs, a single heartbeat ping at the end of the execution is sufficient. The goal is to match the monitoring interval to your Service Level Objectives. Don't over-monitor low-priority tasks; it only leads to unnecessary noise and increased cloud costs.
What happens if my monitoring service itself goes down?
Reliable monitoring services use multi-region architecture to prevent total outages. You should also check the provider’s public status page for transparency. If a monitor fails, you lose visibility, but your tasks should continue running independently. Choosing a provider with a principled commitment to uptime and geographic redundancy is the best way to mitigate this risk.
Is it possible to monitor APIs that require complex authentication like OAuth2?
Modern tools fully support complex authentication methods like OAuth2, Bearer tokens, and API keys. You can configure the monitor to fetch a new token before running each check. This ensures your API endpoint monitoring for automated tasks reflects the actual security requirements of your production environment. Always use secure secret management to handle these credentials rather than hardcoding them into your scripts.
How do I prevent monitoring traffic from skewing my analytics data?
You can prevent skewing your data by filtering out specific User-Agents or IP addresses associated with your monitoring service. Most professional tools provide a static list of IP ranges for their global vantage points. Simply exclude these from your internal analytics dashboard. This keeps your business metrics honest and ensures your automated traffic doesn't inflate your real user session counts.
What are the most important metrics to track for background automated tasks?
Execution integrity is the most critical metric. You must track P99 latency to identify slow-burn failures where tasks gradually lose efficiency. Success rates and payload validation errors are also vital. These metrics tell you if the task finished, how long it took, and if the data was correct. Monitoring these three pillars provides a complete picture of your automation health.
How can AI help in monitoring high-frequency API endpoints?
AI excels at identifying patterns in high-frequency data that humans might miss. It distinguishes between a transient network blip and a genuine architectural failure. This reduces alert fatigue by silencing non-critical noise. Effective API endpoint monitoring for automated tasks now uses AI to draft incident summaries. This helps your team understand the root cause faster, reducing your Mean Time to Recovery during complex outages.


